


What is it?
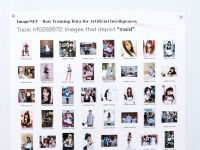
These thumbnails are real-world screenshots from an illegitimately-acquired copy of the ImageNet dataset.
ImageNet is a massive dataset of more than a million images that depict tens of thousands of nouns. For example, the term “cat” has 1,831 photos of cats. (Technically, it is organized by “WordNet synsets,” such as “n02121808” for “domestic cat, house cat, Felis domesticus, Felis catus,” but close enough.)
ImageNet was the raw training data used to train many neural networks (“AIs”) that recognize images. They are shown the desired input and output, and left alone for thousands or millions of iterations until they learn to recognize the desired topics correctly. (Oversimplifying, don’t @ me.)
See “The data that transformed AI research—and possibly the world” for more about ImageNet.
For “Probing ImageNet,” I chose the first files, numerically sorted, in each folder for the topics shown; I did not curate the selections in any way. I styled the print-outs’ typography to fit within the exhibition theme.
The topics I chose:
- “boss”
- “editor”
- “maid”
About the Series
This is part of my “Algorithm” body of work:
-
 “Illegal in Illinois”
“Illegal in Illinois”
-
 “Morale is Mandatory (Algorithm Livery)”
“Morale is Mandatory (Algorithm Livery)”
-
 “Probing GauGAN2”
“Probing GauGAN2”
-
 “Feedback Loop”
“Feedback Loop”
-
 “Probing DALL-E Mini”
“Probing DALL-E Mini”
-
 “Probing ImageNet”
“Probing ImageNet”
-
 “Snap Judgment”
“Snap Judgment”
-
 “Data Chains”
“Data Chains”
-
 “Print/Shred”
“Print/Shred”
More details at “About Algorithms,” the companion site for this work.








